[GPU FUTURE] 그래픽 카드의 미래 2부
GPU FUTRE 은 총 3부로 구성되는 칼럼이다. 이번에는 현재 그래픽 카드의 발전 현황과 어떤 상태에 처해 있는지에 대하여 알아볼 것이다. 만약 GPU 또한 CPU 처럼 기존의 방식대로의 발전에 한계가 왔다면, 다른 방법을 모색해야 할 것이다.
[GPU FUTURE] 그래픽 카드의 미래 1부에서는 GPU의 경우, CPU와는 다르게 일반적으로 연산유닛만 더 박으면 성능 향상으로 이어진다는 말을 했다. 하지만 과거 CPU가 클럭만 올리면 되었다가 INTEL에서 계란 굽는 보일러 프레스캇의 등장으로 멀티코어로 선회했듯이 - GPU도 단순히 연산유닛만 더 박기에는 한계에 부딛히게 되었다.
그럼 누구의 잘못으로? 연산 유닛을 더 박는 설계를 못하는 기존의 양대산맥 NVIDIA와 AMD의 잘못인가? 전혀 아니다. 문제는 공정 전환에 따른 반도체 제조사(=파운드리 업체, TSMC)에게 있었다. 바로 새로운 공정으로 전환하면서 공정 개발비용과 생산비용이 폭증하게 되었고, 이것이 GPU 업체에 전가된 것이다. 단순비교로 28nm → 16nm는 2.1배, 16nm → 7nm는 2.8배, 7nm → 5nm는 1.8배의 개발비용이 들게 된다. 28nm까지는 다음 세대 공정의 개발비용이 1.4배를 넘지 않은 것과 비교하면 큰 문제다.
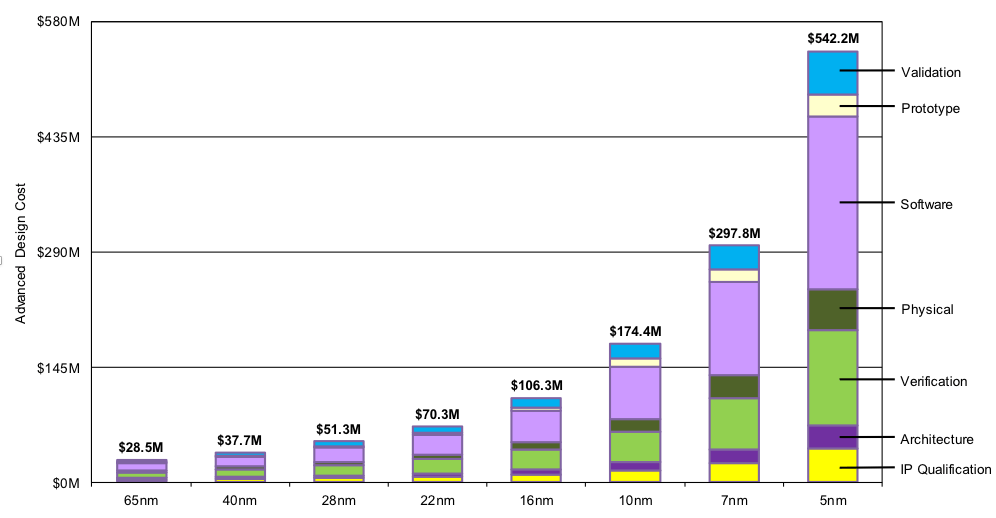
OK. 그럼 한발 양보해서 신 공정 개발 비용이 늘어난 만큼, 반도체 밀도가 늘어났으면 그만큼 상쇄될테니 이것을 확인해 보자. 만약 개발 비용만큼 밀도가 늘어나지 않으면, 사실상 이전과 같은 방법으로 생산하기에는 동 성능대 판매 가격이 터무니 없이 높아질 수도 있겠다.
wikichip 자료를 근거로 TSMC 공정의 개발비용과 밀도 변화(=CPP x MMP)를 비교해 보겠다. SRAM의 크기는 연산유닛의 사이즈와 비슷하다고 보면 된다. (DRAM은 다르다)
| Process | 65 | 40 | 28 | 16 | 7 | 5 | ||||||
| 1st Production | 2005 | 2008 | 2011 | 2015 | 2018 | 2020 | ||||||
| V | △ | V | △ | V | △ | V | △ | V | △ | V(E) | △(E) | |
| Contacted Gate Pitch (nm) | 160 | 0.67 | 162 | 1.01 | 117 | 0.72 | 90 | 0.77 | 57 | 0.63 | 54 | 0.95 |
| M1P/MMP (nm) | 180 | 0.75 | 120 | 0.67 | 90 | 0.75 | 64 | 0.71 | 40 | 0.63 | 36 | 0.9 |
| SRAM bit cell(HD) | .499 | 0.50 | .242 | 0.46 | .127 | 0.52 | .074 | 0.58 | .027 | 0.37 | .021 | 0.78 |
| Design Cost ($M) | 28.5 | - | 37.7 | 1.32 | 51.3 | 1.36 | 106 | 2.07 | 298 | 2.81 | 542 | 1.82 |
| $M/bit cell (relative) |
.057 |
- |
.156 | 2.74 | .404 | 2.59 | 1.43 | 3.54 | 11.0 |
7.69 | 25.8 |
2.34 |
위 표에서는 맨 밑의 항목만 보면 된다. 1 bit cell 당 개발 비용(상대값)이 어떻게 변화해 왔느냐다. 16nm까지는 그래도 3배수 이내였지만, 7nm로 넘어가는 쪽에서 약 7.7배수 - 이전에 비하여 2배나 폭증하는 비용을 볼 수 있다. 즉 16nm에서 7nm로 넘어간다고 생산비용에서 이득이 그렇게 크지 않다는 거다. 이게 중요한 이유는, 기존의 공정 이전(28nm → 16nm)은 같은 크기의 칩에 더 많은 연산 유닛을 집어 넣을 수 있게 되어 얻는 (1)성능 향상과 (2)생산단가 하락을 누리고 있었다. 하지만 7nm부터는 이것이 힘들어졌다는 것이고, 무작정 공정을 이전하여 연산 유닛을 많이 박는 것보다는 다른 방법을 찾아야 하도록 바뀌었다는 것을 시사한다.
이것이 AMD에서 상대적으로 작은 GPU 칩(Navi10; RX5700XT)을 7nm로 내놓았지만, 큰 GPU 칩(Navi20; RX5800XT같은 플래그십)을 내놓지 못한 이유다. 당연하겠지만 반도체 공정에서 칩이 커질수록 수율은 급격히 낮아진다. NVIDIA가 아직 7nm로 가지 않고, 12nm(사실상 TSMC 16nm)를 유지하는 이유기도 한다.
실례로 비슷한 성능의 GTX980Ti / GTX1070 / RX5700의 생산비용을 추정해 보자. 여기서 중간 중간에 컷칩이 섞여 있다. 하지만 수율을 추정할 수 있는 것은 풀칩 기준에서만 가능하므로, 풀칩 수율을 추정하고 이를 풀칩대비 커팅칩의 성능 비율만큼 축소하여 비교하면 될 것 같다. 실제로는 커팅칩의 생산단가는 (불량칩 재활용이므로) 더 낮아질 것이다.
| GTX980Ti(GM200) |
GTX1070(GP104) | RX5700(Navi10) |
| 2015 Q1 | 2016 Q1 | 2019 Q1 |
| 601㎟ | 314㎟ | 251㎟ |
| 24.30119mm x 24.74130mm | 16.16010mm x 19.42950mm | 17.58417mm x 14.27421mm |
| 28nm | 16nm | 7nm |
| 풀칩 | GTX1080 커팅칩 | RX5700XT 커팅칩 |
관련 자료를 찾아보면, 2014 Q2의 시기에 TSMC의 28nm wafer 가격은 $5,850 였다고 한다. 여기서는 수율을 16nm의 초기 수율과 비슷하다고 추정하겠다. 기존의 자료와 합쳐서 보면 300mm Wafer 가격은 아래와 같다. 판매하기 전의 약 반년전부터 생산한다고 가정한 수율과 가격을 사용한다. 만약 이전 자료가 없다면 출시일에 근접한 값을 사용했다.
| TSMC |
28nm | 16nm | 7nm(ArFi) |
| production | 2014 Q2 | 2016 Q2 | 2019 Q1 |
| wafer price($) | 5,850 | 8,400 | 9,965 |
| Defect Density | 0.2167(E) | 0.2167 | 0.295 |
| Scribe Lane/Edge Loss |
0.37599 / 3 | ||
아래의 표는 위의 자료를 바탕으로 추정한 칩별 생산 단가이다.
| Chipset | GM200 | GP104 | Navi10 |
| Price (Relative) | $216.67 | $90.32 | $87.41 |
| by Cutchip(E) | - | $65.79 | $71.23 |
같은 성능 기준이라면 28nm → 16nm의 경우 약 70%의 단가 절감이 이뤄졌고, 16nm → 7nm의 경우 약 9%의 단가 상승이 일어났다. 즉, 16nm까지는 단순히 공정만 줄여도 같은 성능에서 생산 단가가 줄었지만 7nm부터는 생산단가가 상승하는 현상이 나타난다.
이전에는 단순히 공정만 줄이면 GPU 성능도 오르고, 생산 단가도 줄었다. 그래서 과거 2000년 까지의 CPU 제조사들이 그랬듯이 개꿀타임을 지나왔다. 하지만 7nm 부터는 이것이 불가능해졌고, GPU의 성장이 NVIDIA 20시리즈 이후 더뎌지는 것(=정체)이 당연한 사실이 되었다. 즉, 만약 더 높은 성능의 그래픽 카드를 바라면 더 높은 가격을 지불할 수 밖에 없다.
그렇다면 그래픽 제조사들은 이런 한계를 어떻게 해쳐나갈 것인가? 더 좋은 성능을 비슷한 가격 (더 낮은 가격)에 내놓지 않는다면 - 소비자는 새로운 제품을 굳이 구매하려 하지 않을 것이다. 그렇다면 그래픽 제조사가 이익 감소를 감내하고서라도 그래픽 카드를 저렴하게 낼 것인가? 이는 자본주의 원리는 근간부터 무시하는 가정이다. 이를 위한 한 가지 방법이 있다. 이를 마지막 3부에서 다뤄보고자 한다.
2부 요약,
1. GPU 제조사들의 개꿀타임은 너무나 비싸진 신 공정 Wafer 가격 때문에 이제 끝이 났다
2. 새로운 그래픽카드를 기존과 비슷한 가격으로 출시하려면 새로운 방법을 모색해야 한다