[GPU WAR] 16/14nm는 NVIDIA의 편, 7nm는 AMD편을 드는 파운드리 업체
일단 시작하기에 앞서, 2016년부터 GPU생산단가를 추청하는 것이 상당히 무모한 도전이었고, 생각보다 자료가 정확하지 않다는 것을 깨닫게 되었다. 가장 확실한 정보는 2019년도 TSMC발 수율표이지만, ZEN의 수율표와 비교하면 뭔가 아리송해 지는 것을 느낄 수 있다.
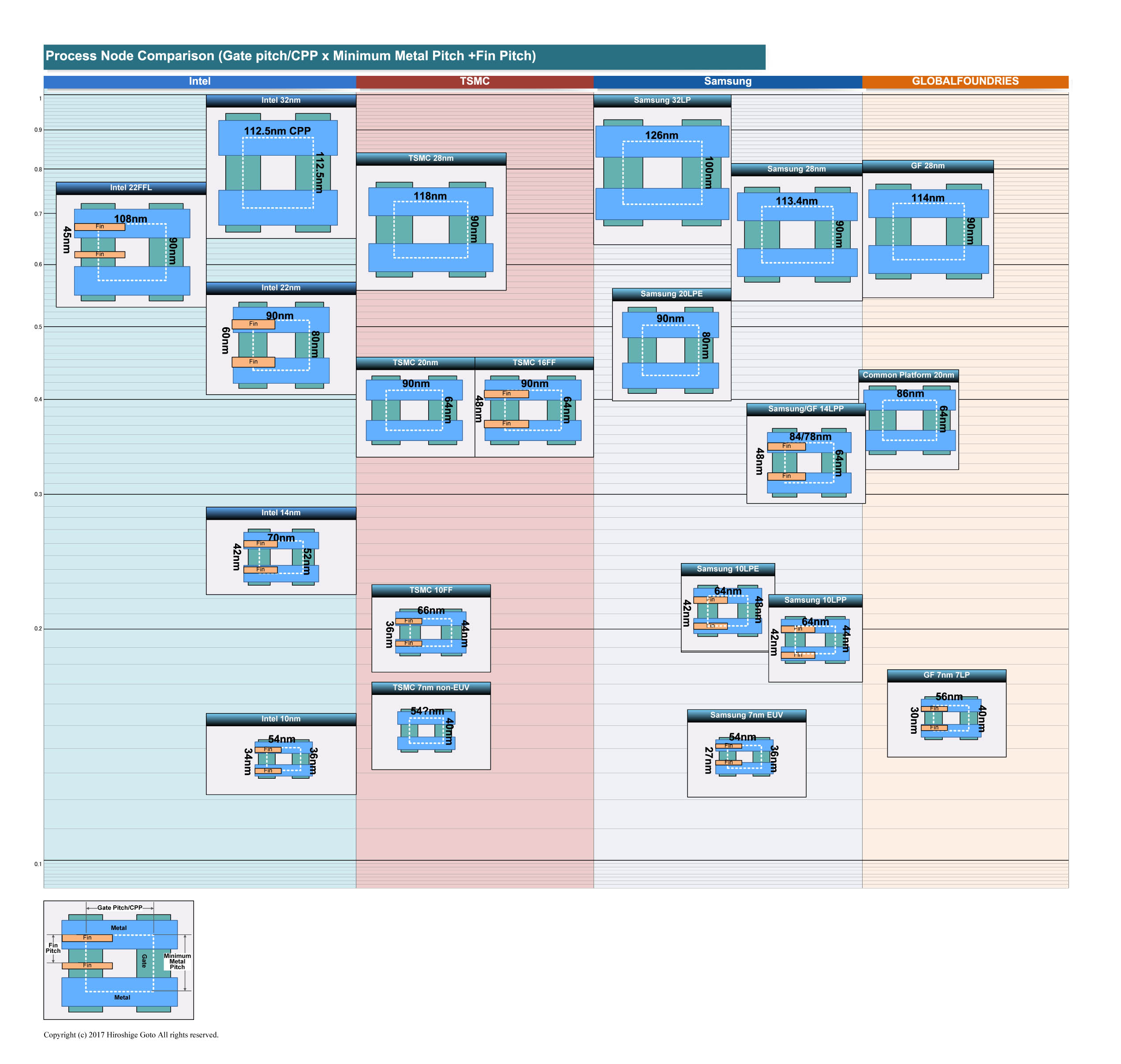
위 자료는 2018년 7월 3일 자료로, 각 파운드리별로 공정 미세 정보를 나타낸다. 사실상 미세공정일수록 생산 난이도는 높아지고 수율은 낮아진다. 엄밀하게 말하면 TSMC 16FF는 Global Foundries(GF) 14FF보다 덜 미세하나, 큰 차이는 없으므로 일반적으로 완전 같은 세대로 본다. 아이폰6S의 A9는 16FF와 14FF로 같이 생산되었으나 성능의 편차가 거의 없다고 밝혀졌다.
거의 동일한 미세정도의 공정이라고 본다면 수율도 경쟁사이므로 흡사해야 할 것이다. 그런데 자료를 보면 조금 이상하다.
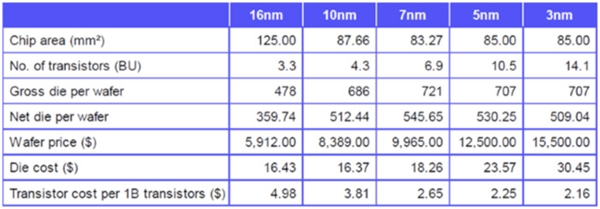
위의 표를 기준으로 2019년도 TSMC 16nm 125㎟ Die의 평균 수율은 대략 78.29%가 나온다. 그런데 2018년도 7월달에 GF 12nm 192㎟ Die인 ZEN+(Zeppeline) 수율이 90%를 넘는다고 기사에 났었다. 사이즈가 크면 수율이 낮아야 되는 것이 정상인데, 이상하게 수율이 더 높게 나왔다. 왜 이런 것인가? 이에 대하여 몇가지 가정을 해 보고자 한다.
- 파운드리에서 칩셋을 생산할 경우, (해당 공정이 충분히 성숙했더라도) 초반에는 수율이 낮았다가 이후 수율이 90%까지 상승한다. 공정이 성숙할 수록 수율이 오르는 기간은 짧아진다.
- GF는 TSMC보다 공정 기술이 떨어진다. GF 14FF의 경우, 삼성이 GF에 전수한(?) 공정기술이다.
- TSMC의 수율은 16nm 웨이퍼에서 생산되는 전 제품 - AP(모바일 칩셋)/GPU칩셋을 모두 포함한 수율의 평균이다. 즉, 이 중에서는 이제 막 생산 시작한 모델도 있어서 수율이 낮아보이는 효과가 있다.
- GF는 14nm 에서 제플린만 2년 생산했기에 수율 향상이 눈에 띄게 보였다.
- 그렇기 때문에 생산 단가는 라이젠 CPU 수율을 배제하고서 TSMC만의 자료만으로 추정하고자 한다.
- Edge Loss : 3mm / Scribe Lane : 0.365mm (TSMC Gross die per wafer 역계산한 값) 를 전제로 한다.
- Die가 커질수록 불량률은 커지나, 여기서는 Die Size와 상관없이 Defect Density는 동일하다고 보고 계산한다. 즉, 큰 다이 일수록 계산된 값보다 실제 생산가격이 더욱 더 올라갈 것이다.
이 가정을 기반으로 GPU 생산단가를 추적하고자 한다. 제일 먼저 필요한 작업은 아래와 같다. 2019년의 수율은 있기 때문에 2015~2016년 중의 16nm 수율을 추정해야 한다. 이 또한 125㎟ Die 기준 수율로 변환되어야 한다. 다행히 Apple iPhone 6S의 A9칩 생산 단가와 수율에 관한 자료를 찾았기에 해당 부분을 추정가능하다.
해당 글에서 보면 Q4'15년의 16nm 12인치 웨이퍼 가격은 $8400였다고 한다. 또한 A9의 수율을 kirin950 수율이 80% 였기에, 이 또한 80%로 수율을 추정한다. A9는 104.5㎟의 다이로 215*261 비율이다. 여기서 9.27806x11.26313인 것을 이용해서, Defect Density가 0.2167인 것을 알 수 있다. 2019년의 Defect Density는 0.2로 생각보다 큰 차이가 없다는 것을 알 수 있다. 그렇다면 TSMC는 웨이퍼 단가를 줄이는 대신 수율은 그렇게 많이 높이지 않았다는 결론이 나게 된다. 그렇다면 여기서 Q4'15를 Q2'16자료로 써도 큰 차이가 없다고 추측할 수 있다. 웨이퍼 단가와 불량률은 1차 함수 형태로 감소해 왔다고 친다.
| TSMC 16FF | Q2'16 | Q2'17 | Q2'18 | Q2'19 |
| wafer price($) | 8,400 | 7,570 | 6741 | 5,912 |
| Defect Density | 0.2167 | 0.2111 | 0.2056 | 0.2 |
| TSMC 7nm |
wafer price 9,965 / Defect Density 0.295 / Scribe Lane 0.37599 | |||
이제 이 표를 기반으로 GPU 칩셋 수율을 계산할 것이다. 계산 순서를 나열하자면.
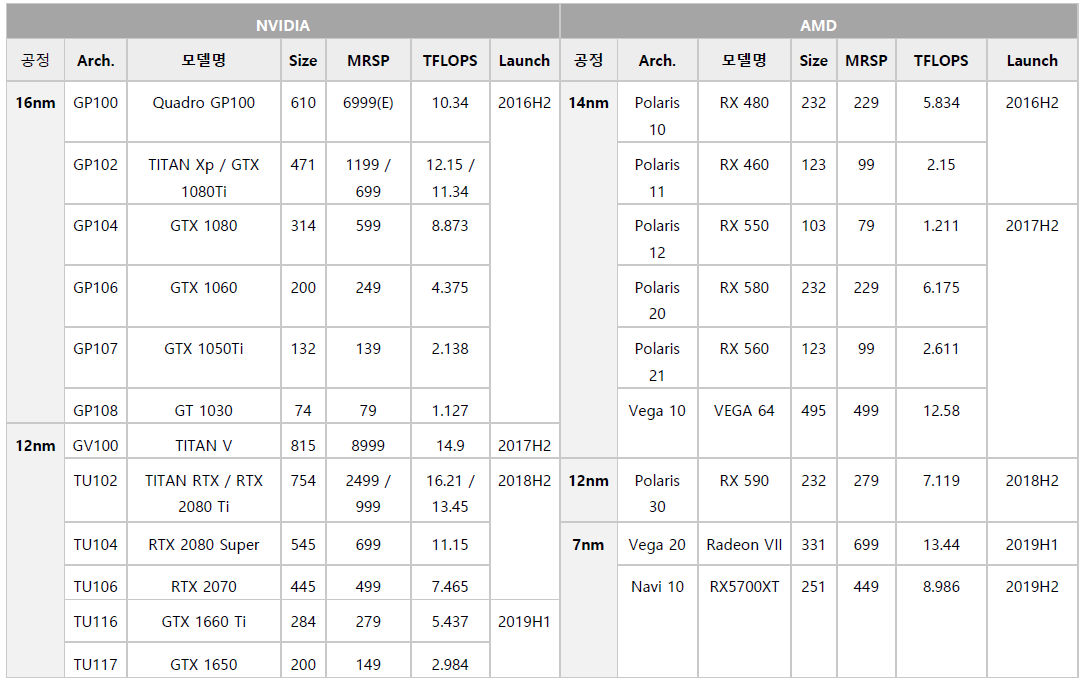
1. 2016년부터 출시된 GPU 모델을 정리한다. 출시 시기는 대충 정리한 것으로 1~2개월의 오차는 있다. 하지만 크게 신경쓸 저옫는 아니다.
2. 위의 수율표를 기반으로 NVIDIA GPU칩셋 단가를 계산한다. 12nm는 16nm 공정개선 버전 리네이밍으로 칩셋 사이즈의 변화는 없다. 웨이퍼 단가가 조금 상승할 것이지만, 이는 무시한다. GF 14FF=TSMC 16FF / TSMC 12nm = GF12nm로 계산할 것이다. H2'16에 출시된 GPU는 H1'16~18에 이미 생산이 들어간 물량이므로 Q2'16~18의 수율표를 사용하여 계산한다. H1'19의 경우는 Q2'19의 자료를 쓴다.
3. 마찬가지로 AMD GPU칩셋 단가를 계산한다.
4. NVIDIA와 AMD의 생산단가를 비교한다. Profit! 참 쉽죠??
1
2
16nm

(1) 610㎟ = 105x *127x = 13,335x^2 = 22.45731mm x 27.16265mm
(2) Defect Density = 0.2167; Good Die = 26

(3) 16nm 12인치 웨이퍼 단가 $8,400 → GP100 칩셋 단가 = $8,400/29 = $289.66

(1) 471㎟ = 112x *138x = 15,456x^2 = 19.55149mm x 24.09023mm
(2) Defect Density = 0.2167; Good Die = 44
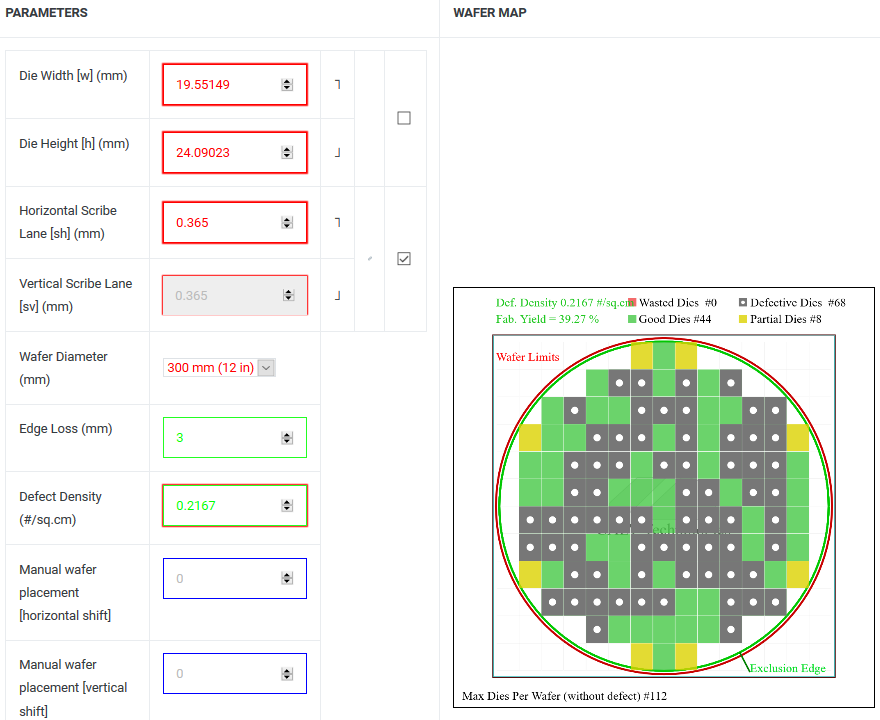
(3) 16nm 12인치 웨이퍼 단가 $8,400 → GP102 칩셋 단가 = $8,400/44 = $190.91

(1) 314㎟ = 89x *107x = 9,523x^2 = 16.16010mm x 19.42950mm
(2) Defect Density = 0.2167; Good Die = 93

(3) 16nm 12인치 웨이퍼 단가 $8,400 → GP104 칩셋 단가 = $8,400/93 = $90.32

(1) 200㎟ = 96x *64x = 6,144x^2 = 17.32051mm x 11.54701mm
(2) Defect Density = 0.2167; Good Die = 182
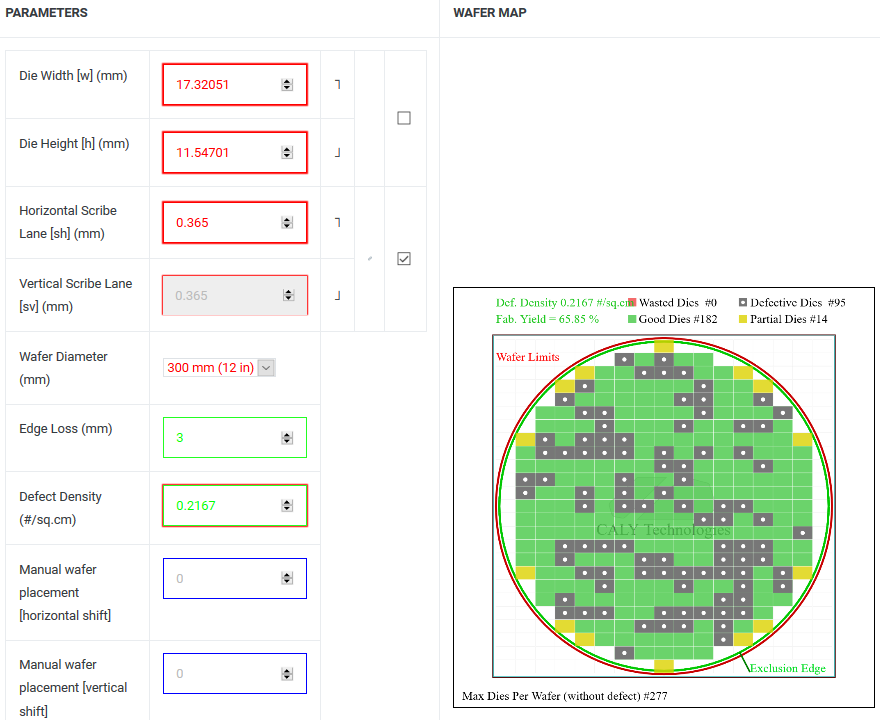
(3) 16nm 12인치 웨이퍼 단가 $8,400 → GP106 칩셋 단가 = $8,400/182 = $46.15

(1) 132㎟ = 85x *81x = 6,885x^2 = 11.76939mm x 11.21554mm
(2) Defect Density = 0.2167; Good Die = 330
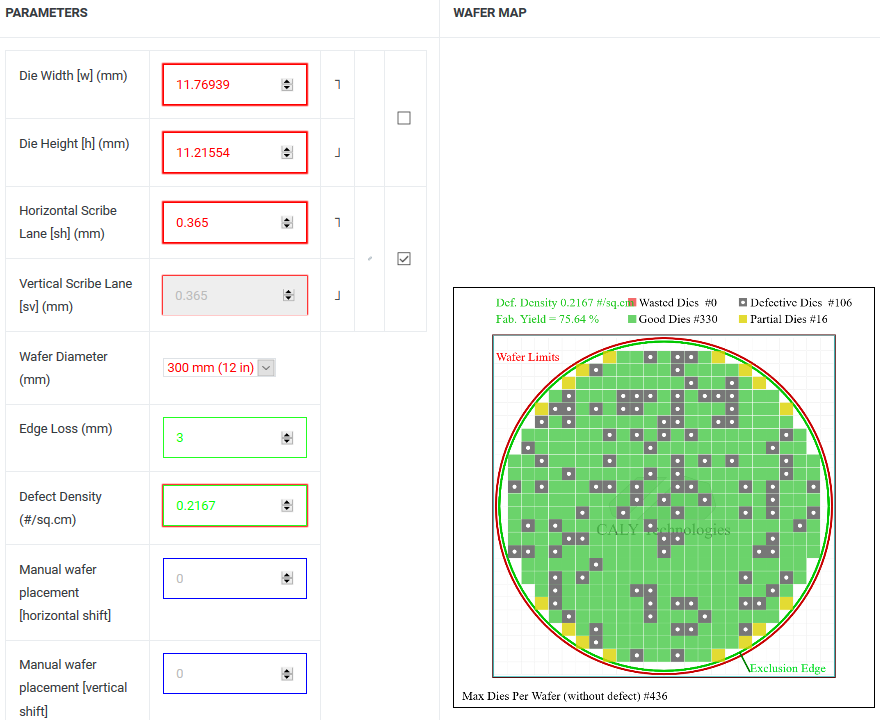
(3) 16nm 12인치 웨이퍼 단가 $8,400 → GP107 칩셋 단가 = $8,400/330 = $25.45

(1) 74㎟ = 70x *82x = 5,740x^2 = 7.94800mm x 9.31052mm
(2) Defect Density = 0.2167; Good Die = 668

(3) 16nm 12인치 웨이퍼 단가 $8,400 → GP108 칩셋 단가 = $8,400/668 = $12.57
12nm

(1) 815㎟ = 95x *121x = 11,495x^2 = 25.29577mm x 32.21882mm
(2) Defect Density = 0.2111; Good Die = 13

(3) 12nm 12인치 웨이퍼 단가 $7,570 → GV100 칩셋 단가 = $7,570/13 = $582.31

(1) 754㎟ = 106x *132x = 13,992x^2 = 24.60660mm x 30.64218mm
(2) Defect Density = 0.2056; Good Die = 18

(3) 12nm 12인치 웨이퍼 단가 $6,741 → TU102 칩셋 단가 = $6,741/18 = $374.5

(1) 545㎟ = 133x *123x = 16,359x^2 = 24.27569mm x 22.45045mm
(2) Defect Density = 0.2056→(19Q2)0.2; Good Die = 35→(19Q2)36

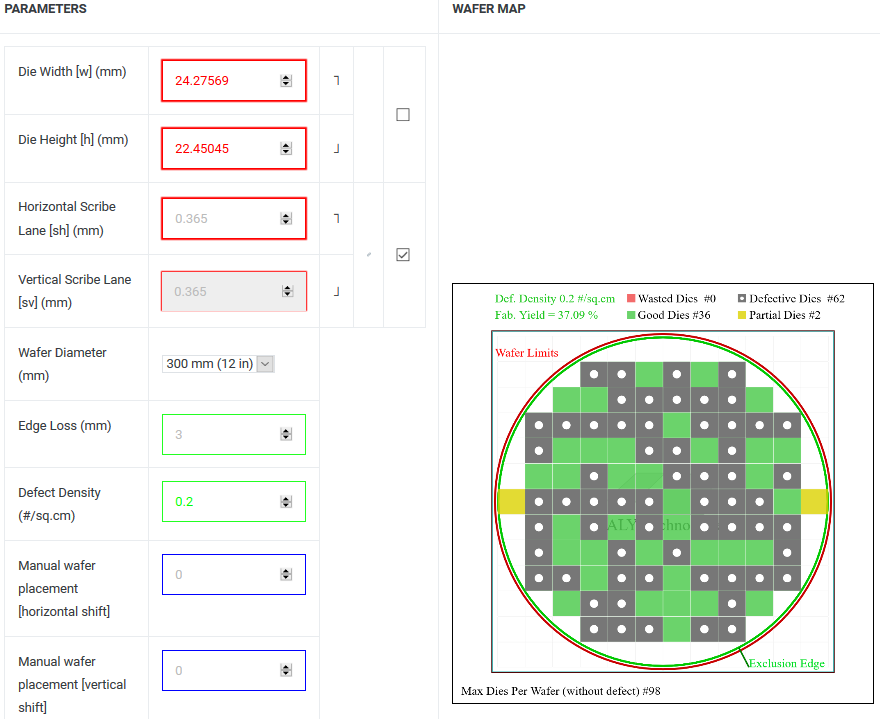
(3) 12nm 12인치 웨이퍼 단가 $6,741(→(19Q2) $5,912) → TU104 칩셋 단가 = $6,741/35 = $192.6→(19Q2) $164.22

(1) 445㎟ = 131x *101x = 13,231x^2 = 24.02453mm x 18.52273mm
(2) Defect Density = 0.2056; Good Die = 50
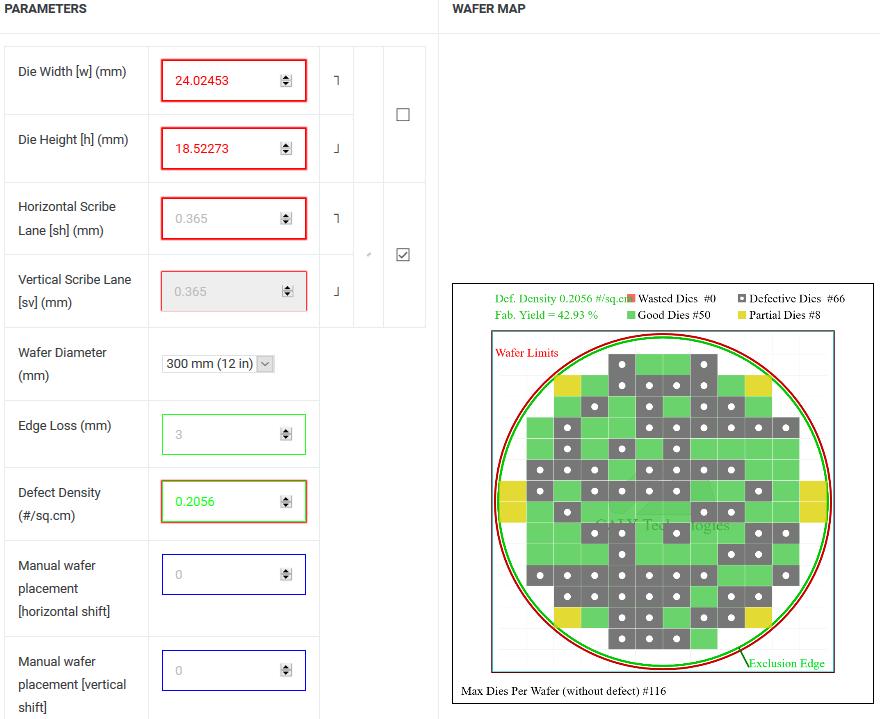
(3) 12nm 12인치 웨이퍼 단가 $6,741 → TU106 칩셋 단가 = $6,741/50 = $134.82

(1) 284㎟ = 121x *70x = 8,470x^2 = 22.15659mm x 12.81786mm
(2) Defect Density = 0.2; Good Die = 110
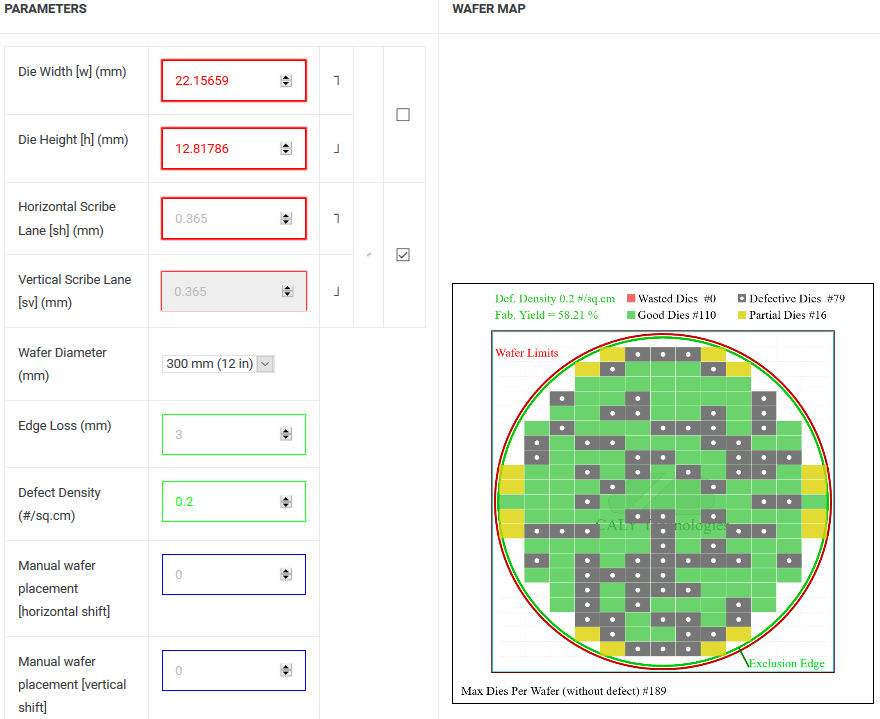
(3) 12nm 12인치 웨이퍼 단가 $5,912 → TU116 칩셋 단가 = $5,912/110 = $53.75

(1) 200㎟ = 101x *99x = 9,999x^2 = 14.28427mm x 14.00141mm
(2) Defect Density = 0.2; Good Die = 190
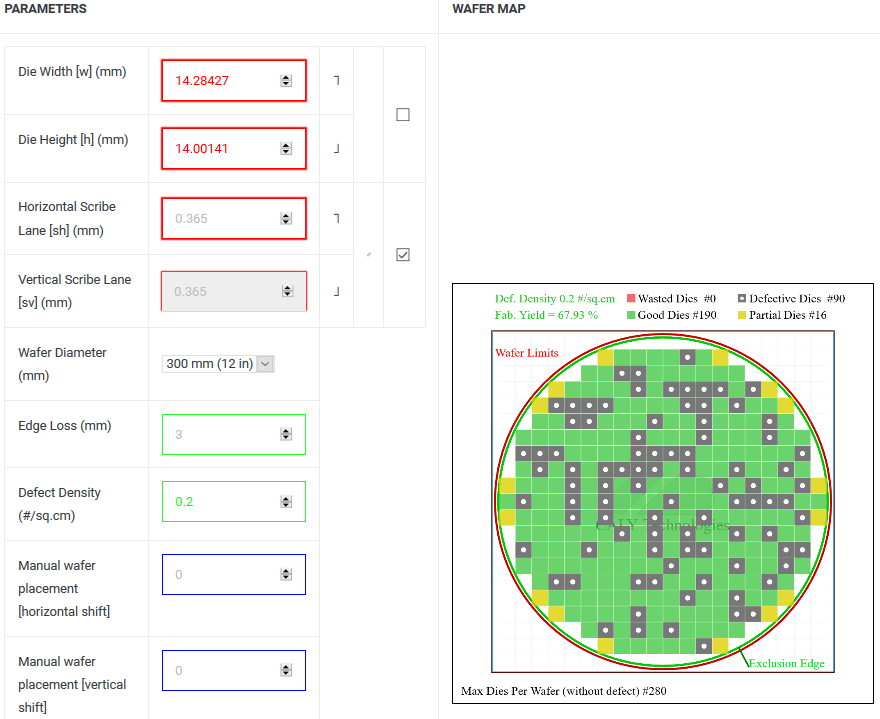
(3) 12nm 12인치 웨이퍼 단가 $5,912 → TU117 칩셋 단가 = $5,912/190 = $31.12
3
14nm

(1) 232㎟ = 321x *250x = 80,250x^2 = 17.25943mm x 13.44193mm
(2) Defect Density = 0.2167; Good Die = 148

(3) 14nm 12인치 웨이퍼 단가 $8,400 → Polaris10 칩셋 단가 = $8,400/148 = $56.76

(1) 123㎟ = 90x *100x = 9,000x^2 = 10.52141mm x 11.69045mm
(2) Defect Density = 0.2167; Good Die = 359
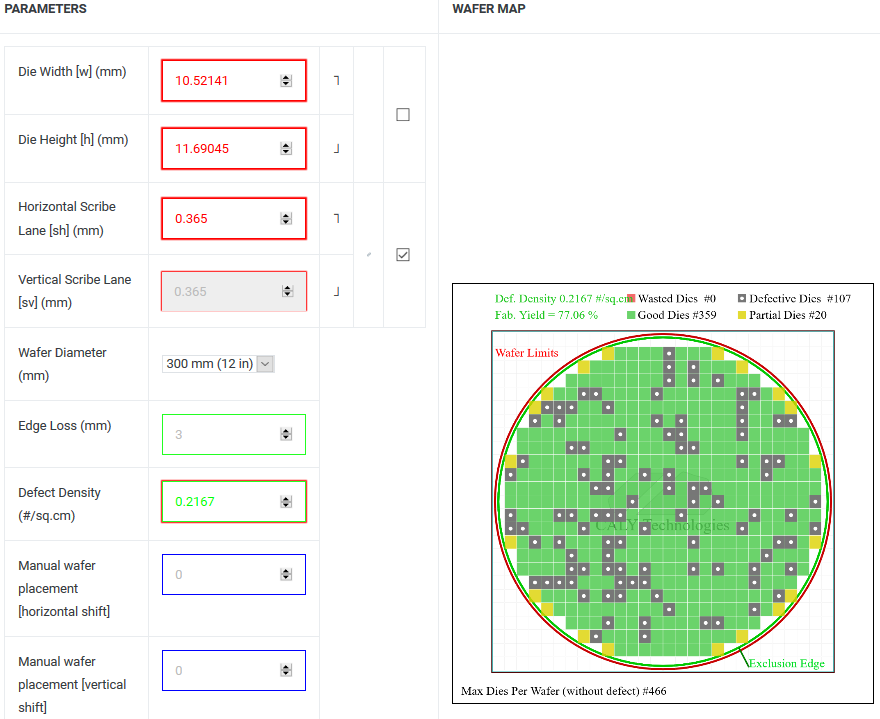
(3) 14nm 12인치 웨이퍼 단가 $8,400 → Polaris11 칩셋 단가 = $8,400/359 = $23.4

(1) 103㎟ = 72x *101x = 7,272x^2 = 8.56888mm x 12.02024mm
(2) Defect Density = 0.2111; Good Die = 449
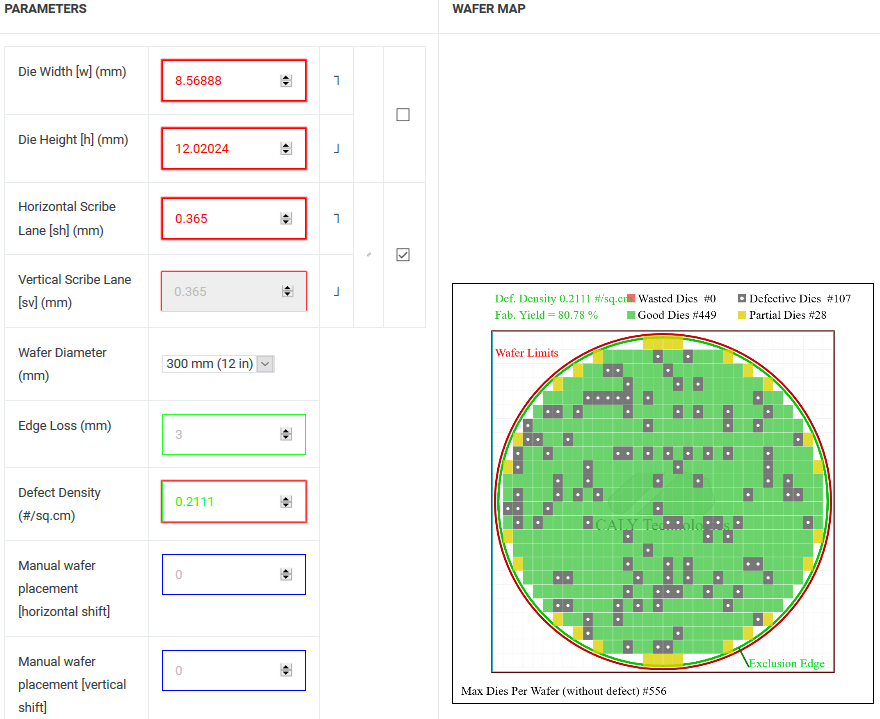
(3) 14nm 12인치 웨이퍼 단가 $7,570 → Polaris12 칩셋 단가 = $7,570/449 = $16.86

(1) 232㎟ = 321x *250x = 80,250x^2 = 17.25943mm x 13.44193mm
(2) Defect Density = 0.2111; Good Die = 150

(3) 14nm 12인치 웨이퍼 단가 $7,570 → Polaris20 칩셋 단가 = $7,570/150 = $50.47

(1) 123㎟ = 90x *100x = 9,000x^2 = 10.52141mm x 11.69045mm
(2) Defect Density = 0.2111; Good Die = 361
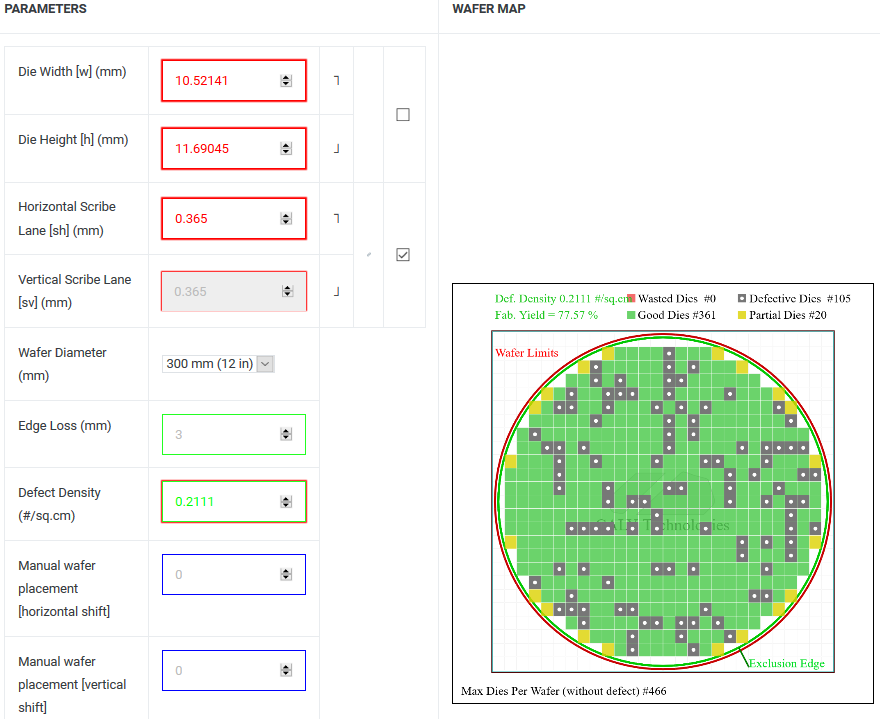
(3) 14nm 12인치 웨이퍼 단가 $7,570 → Polaris21 칩셋 단가 = $7,570/361 = $20.97

(1) 495㎟ = 83x *110x = 9,130x^2 = 19.32615mm x 25.61297mm
(2) Defect Density = 0.2111; Good Die = 41

(3) 14nm 12인치 웨이퍼 단가 $7,570 → Vega10 칩셋 단가 = $7,570/41 = $184.63
12nm

(1) 232㎟ = 321x *250x = 80,250x^2 = 17.25943mm x 13.44193mm
(2) Defect Density = 0.2056; Good Die = 152
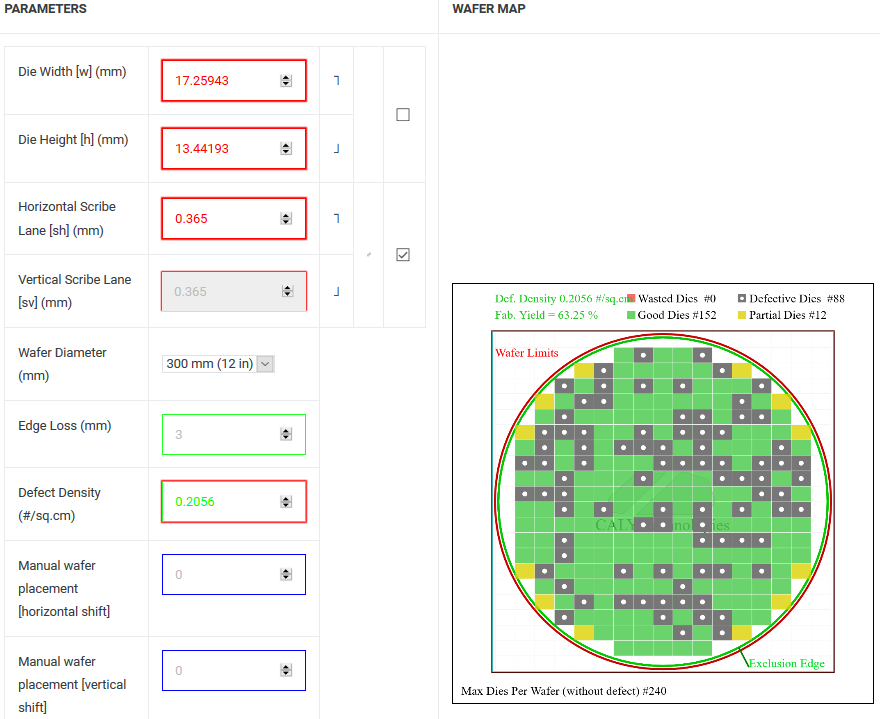
(3) 12nm 12인치 웨이퍼 단가 $6,741 → Polaris30 칩셋 단가 = $6,741/152 = $44.35
7nm

(1) 331㎟ =58x *92x = 5,336x^2 = 14.44555mm x 22.91363mm
(2) Defect Density = 0.295; Good Die = 66

(3) 7nm 12인치 웨이퍼 단가 $9,965 → Vega20 칩셋 단가 = $9,965/66 = $150.98

(1) 251㎟ = 85x *69x = 5,865x^2 = 17.58417mm x 14.27421mm
(2) Defect Density = 0.295; Good Die = 114

(3) 7nm 12인치 웨이퍼 단가 $9,965 → Navi10 칩셋 단가 = $9,965/114 = $87.41
4
칩셋단가&MRSP

위의 그래프는 NVIDIA 풀칩 기준의 생산단가와 MRSP를 나타내고 있다. 흥미로운 것은 16nm에서보다 (16nm리네이밍 공정인)12nm에서 판매이율이 상승했다는 사실이다. 특히 최상위 라인업인 GP100/GV100의 경우, 경쟁상대가 없기 때문에 칩셋가격을 $6999/8999로 받아 먹어도 잘 팔리는 소위 배짱장사로 이윤이 극대화 된다는 것을 알 수 있다. GP100의 성능은 1년간 최고였다. 또한 GV100/GP102/TU102 풀칩 성능의 AMD GPU가 출시된 적이 없기에, NVIDIA가 얼마나 남겨먹든 간에 팔릴 수 밖에 없는 것이 현실이다.
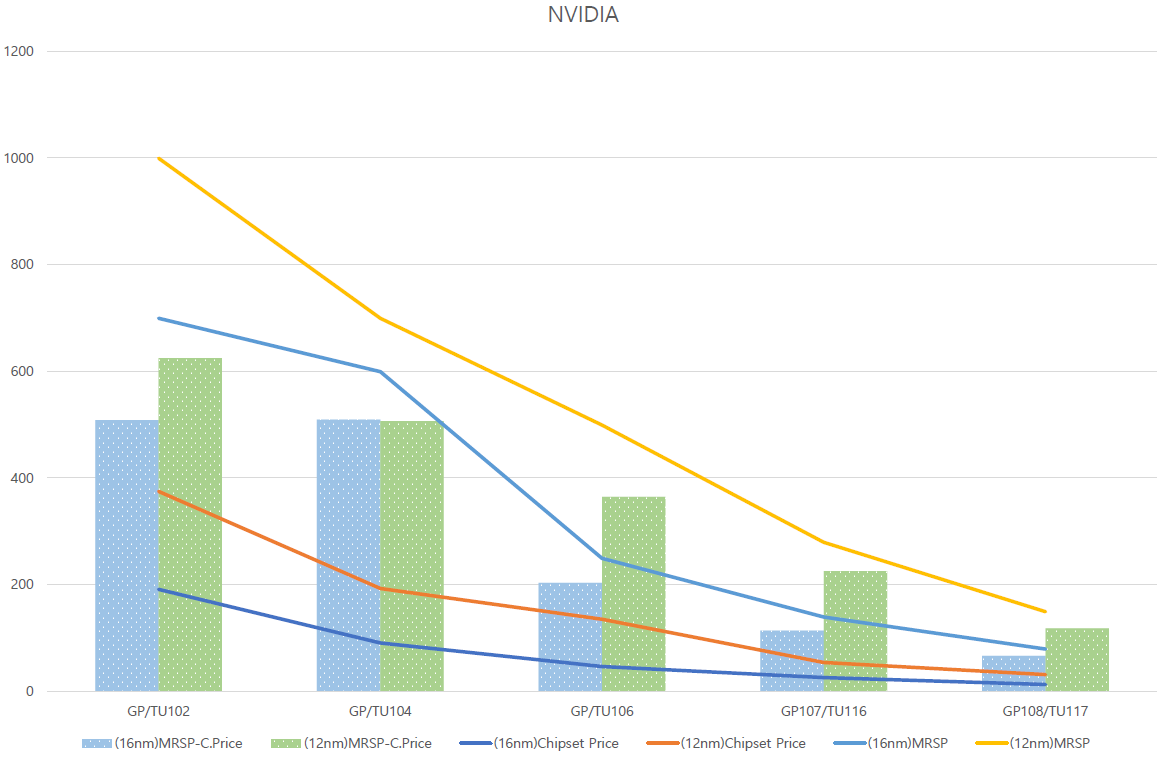
위에서는 최상위칩(GP100/GV100)으로 인하여 그래프의 간격을 실감하기 어려웠다. 여기서는 일반사용자가 살법한 가격대 기준으로 살펴보자. 재미있는 것은 12nm에서 16nm에서보다 이윤이 극대화 되는 부분에서 104라인업은 제외된다는 사실이다. 해당 칩셋만큼은 두 공정에서의 이윤은 큰 차이가 없다. 해당 아키텍쳐의 GPU는 1080/2080으로, NVIDIA에서 해당 라인업의 가격만큼은 적정가로 측정하려 노력했다고 추측할 수 있다. 물론, 2080Ti/2070/2060/1660/1650의 경우 경쟁 상대가 마땅찮기 때문에 이윤은 극대화 한 것으로 보인다. 흥미로운 점은 RTX2070이하 라인업에서 실제로 RayTracing 기능은 프레임 반토막 때문에 쓰기 힘든 기능이다. 하지만 RT코어 탑재를 이유로 이윤을 극대화 한 사실을 알 수 있다. 젠슨 황의 입털기를 세계 최고였다. 실제 쓰지 못하는 기능을 핑계로 칩 크기를 키우고, 이윤은 더 늘린 것이다.

AMD의 경우 실제로 NVIDIA의 최상위 라인업에 대응하는 칩셋이 없다. 그래서 이윤을 극대화하기 보다는 적당한 가성비로 더 많은 판매량을 노리는 소위 가성비 라인업에 집중하는 경향이 크다. 위에서 Vega10/Vega20의 경우 이윤이 많은 것처럼 보이나, NVIDIA의 GPU에 탑재된 GDDR5/GDDR6과는 다르게 더 비싼 HBM메모리가 장착되어 있어 실제로는 Polaris 라인업보다 이윤이 더 적다고 알려져 있다. 7nm에 이르러서야 동급GPU의 이윤에서 AMD가 NVIDIA보다 앞서기 시작했다. 바로 RX5700XT(Navi10)의 (상대적)이윤이 $412이고 RTX2070(TU106)의 (상대적)이윤이 $364로 상황이 역전된 것이다. 이것이 바로 NVIDIA가 GPU의 가격을 무작정 할인해서 팔 수 없는 이유다. 어쨋건 간에 AMD은 매우 강력한 NVIDIA의 GPU에 눌려 2016~2018년의 암흑기를 보내야만 했고, 2019년에 이르러서야 기지개를 펴기 시작했다.
칩셋단가orMRSP&TFLOPS
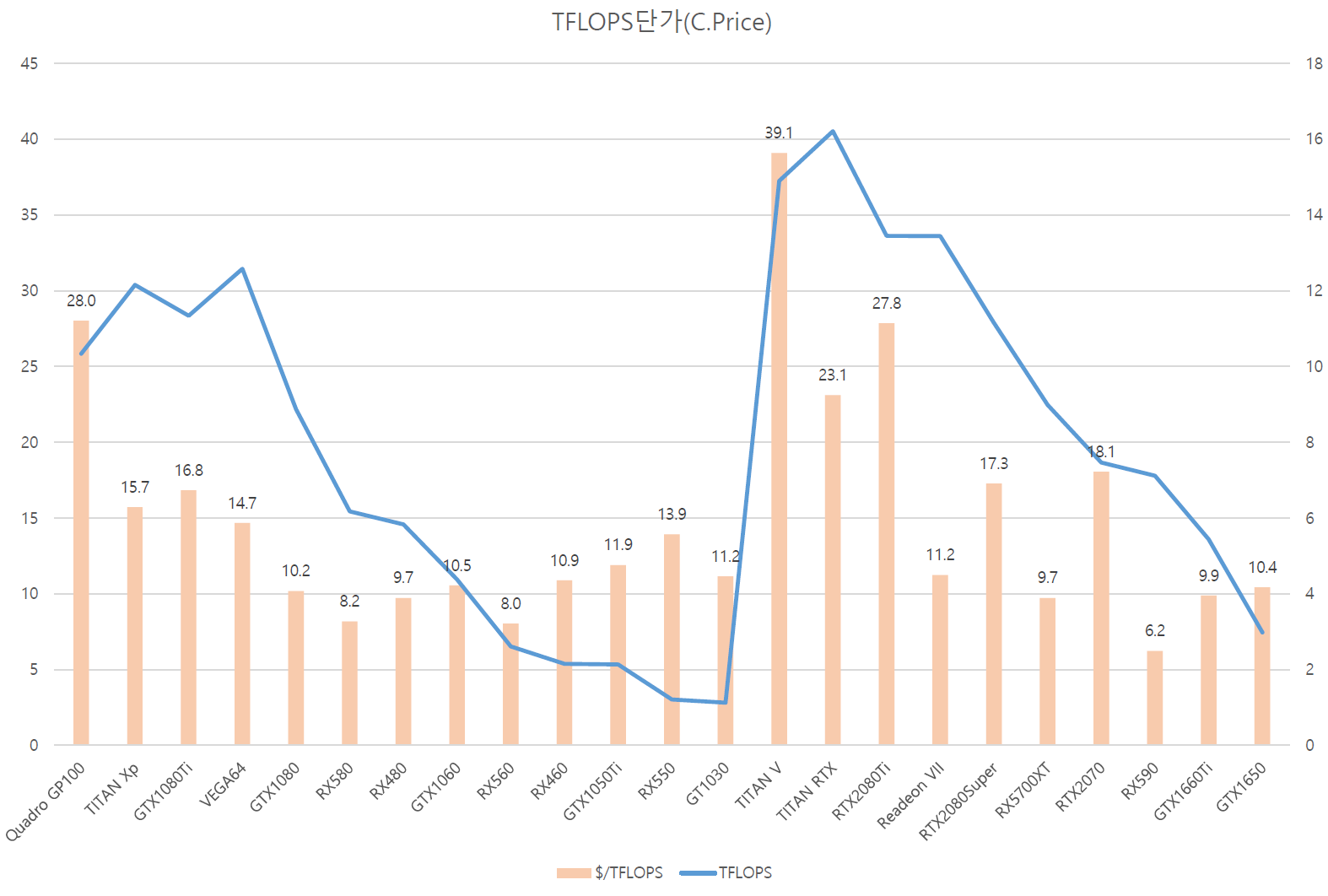
NVIDIA는 라인업을 크게 3가지로 나눈다. 먼저 GTX/RTX와 Quadro라인업의 아키텍쳐 구분이다. 큰 차이는 바로 계산성능을 줄이고 게임성능을 최적화 시킨 것이 GTX/RTX라인업이다. 여기에서 Quadro에서 반정밀도 계산성능을 고자로 만들어서(...) 출시한 것인 TITAN이다. 즉 NVIDIA는 Quadro/TITAN/GTX or RTX로 GPU 라인업이 구분된다.
AMD는 그냥 하나의 아키텍쳐 기반이기에 다 같은 라인업이라고 보면 된다. 다만 R&D비용이 CPU에 집중되는 동안 새로운 아키텍쳐 개발이 더뎠기에, NVIDIA의 최상위 라인업인 TITAN V / TITAN RTX에 비견되는 그래픽은 출시된 적이 없다. 하지만 한가지 확실한 것은 같은 TFLOPS라면 AMD의 GPU가 NVIDIA보다 생산단가가 저렴하다는 사실이다. 하지만 여기서 AMD는 GDDR메모리 대신 HBM메모리를 사용한 VEGA라인업의 경우, 생산단가가 칩셋은 저렴하지만 - 총 단가는 NVIDIA와 비슷할 것으로 보인다. AMD는 여기서 같은 TFLOPS라면 (상대적으로 조금이라도) 더 저렴한 칩셋 단가를 가진다는 점에서, 비록 GCN이 게임에서 그렇게 좋지는 못하지만 계산에서는 상당히 좋은 아키텍쳐임을 알 수 있다.

전체적으로 AMD는 NVIDIA보다 TFLOPS당 가격이 저렴한 것을 알 수 있다. 특히 Radeon VII의 경우 RTX2080Ti와 TFLOPS성능이 거의 동일하지만 $/TFLOPS가 반토막임을 알 수 있다. 즉, 시장에서의 GPU가격은 사실상 계산 성능이 아닌 게이밍 성능으로 결정된다는 사실을 알 수 있다. 그리고 AMD는 생산단가가 NVIDIA와 거의 흡사하지만 MRSP가 저렴한 것을 볼 때, 고성능 그래픽카드를 많이 판매할수록 판매 이윤이 줄어든다는 것도 알 수 있다. RX580과 같은 라인업을 많이 파는 것이 이윤 확대에 도움이 될 것이다.
칩셋단가orMRSP&게이밍성능
게이밍 성능은 TFLOPS와는 조금 다르다. TFLOPS가 낮더라도 클럭이 높거나 아키텍쳐가 최적화 되어 있다면 더 좋은 게이밍 성능을 보장하기도 한다. NVIDIA의 그래픽카드가 그러한 경우다. 다양한 자료를 참고하면 좋겠지만, 한 사이트의 자료가 유용해 보이기에 해당 자료를 참고해서 그래프를 보고자 한다.

AMD는 RX400~Radeon VII에 이르기까지 2016~2018년 동안 같은 게이밍 성능에서, 생산단가가 항상 NVIDIA에 비하여 비쌌다. 2016년의 RX460은 GTX1050Ti보다 성능이 안 좋음에도 1P당 $0.4가 더 비싸게 생산되었다. RX480은 GTX1060보다 게이밍에서 아주 조금 부족하면서도 1P당 $0.3가 비싸게 생산되었다. VEGA64는 GTX1080보다 게이밍에서 약하지만 1P당 생산단가가 2배가 넘는다. 2019년에서 Radeon VII의 게임 성능은 RX5700XT와 비슷하나 1P당 생산단가는 60%정도 더 비싸다. 여기에서 왜 Radeon VII가 일찍 단종 수순에 들어갔는지 알 수 있다. 또한 흥미로운 사실은, RX5700XT는 RTX2070보다 성능이 좋음에도 1P당 생산단가에서 40%정도 더 저렴한 것을 알 수 있다. 여기서 조심스럽게 추측하자면, RTX2070에 들어간 RT코어가 생산단가에서 쓸모없이 차지하는 비용이 좀 된다는 사실이다.
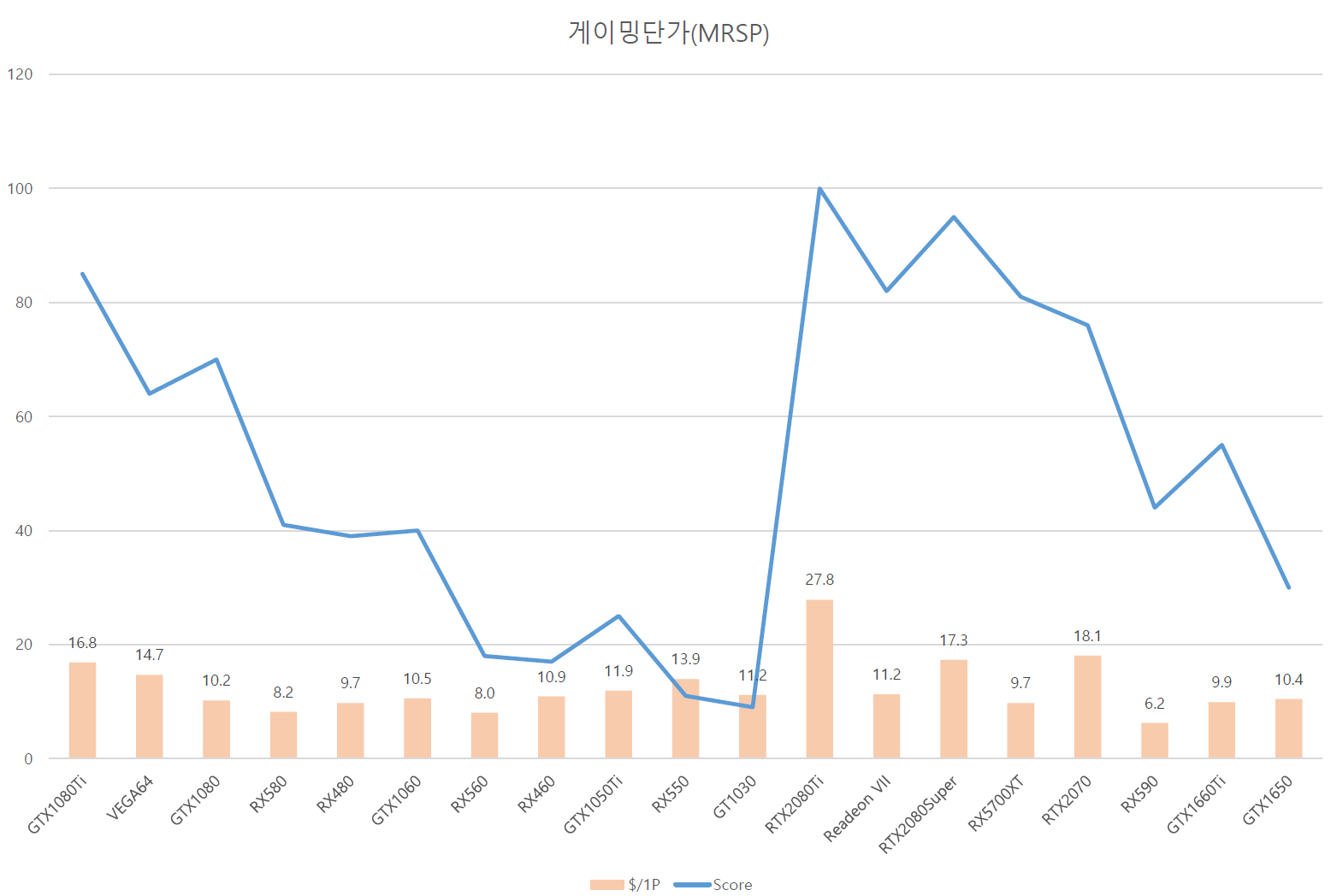
재미있는 것은, 생산단가에서 분명 AMD는 NVIDIA보다 비용을 더 지출한다. 하지만 판매 단가는 비슷하거나 더 저렴하다. 즉, NVIDIA보다 판매 이윤이 더 적다는 것을 의미한다. 또한 TFLPOS결과와는 무관하게 게이밍 성능에 의하여 가격이 책정되는 것을 여기서 확인할 수 있다. VEGA64의 경우 GTX1080보다 1점당 판매가격이 높은 이유는 HBM도입과 패키징 비용이 비싸서 여기서 가격을 더 내릴 수 없었던 이유가 크다. Redeon VII에서도 HBM을 사용했지만, 해당 공정이 성숙했기에 판매가를 더 내릴 수 있었다. 하지만 역시나 VEGA64/Radeon VII에서는 이윤이 매우 적을 것이라고 추측할 수 있다.
결론
>>2016~2019 2분기 = NVIDIA 압승
AMD는 RX400/500/VEGA64/Readeon VII에 이르기까지 NVIDIA에 비하여 게이밍에서 생산단가가 더 비쌌으나 판매가는 비슷하거나 소폭 낮았다. 그래서 그래픽에서의 이윤은 크지 않았다. NVIDIA는 GTX1080/RTX2080에 이르기까지 게이밍에서 AMD보다 생산단가가 저렴했으며 판매가는 비슷하거나 소폭 높았으며, 당대 플래그십에 대하여는 큰 이윤을 남겼다. (빅데이터 처리 시장에서는 최고 플래그십이 아닌 경우에, AMD는 NVIDIA에 비하여 가성비 라인으로 도입하기에 매우 좋은 선택지였다. 그래서 빅데이터 시장에서는 AMD의 경우 경쟁력이 충분하였다.)
>>2019 2분기부터 적어도 2020 1분기 까지 = AMD 판정승
AMD의 RX5700XT는 NVIDIA의 RTX2070보다 소폭 성능이 좋음에도 7nm의 공정에 힘입어 생산단가가 저렴할 뿐더러, 게이밍에서도 충분한 저력을 보여 주었다. 같은 아키텍쳐 기반으로 출시되는 라인업을 생각해 볼 때, 아직 12nm에서 머물고 있는 NVIDIA는 생산단가에서나 판매 대비 이윤에서 이전처럼 이윤을 취하기 어려워 보인다. 또한 단가 경쟁에서 가격을 내릴 여력이 AMD보다 부족한 현실때문에, 늦어도 내년 중후반기에는 차세대 그래픽을 출시해야 할 것으로 보인다.
[참고 링크 List] 더보기를 클릭하세요.
- GPU 목록
www.pcgamer.com/what-nvidias-new-6000-gpu-means-for-gaming/
www.techpowerup.com/gpu-specs/
- 공정 난이도
pc.watch.impress.co.jp/docs/column/kaigai/1130945.html
- Zeppeline Die yield 80%(2Q17) → 90%(2Q18)
www.guru3d.com/news-story/amd-ryzen-14nm-wafer-yields-pass-80-threadripper-cpus-on-track.html
www.reddit.com/r/Amd/comments/6q0ie0/did_amd_waste_two_perfectly_good_8core_die_in/
www.bodnara.co.kr/bbs/article.html?num=156000
- 2019 TSMC 12인치 웨이퍼 수율
news.mydrivers.com/1/634/634825.htm
- 2015.11 Apple A9 수율
www.fool.com/investing/general/2015/11/10/how-much-does-the-apple-inc-a9-cost-to-make.aspx
www.anandtech.com/show/9686/the-apple-iphone-6s-and-iphone-6s-plus-review/3
- 게이밍 성능 랭크